Label-Supervised Routing in Upcycled Mixture of Experts
Introduction
Mixture of Experts (MoE) models extend the standard Transformer architecture by modifying the feed-forward part of each block. Instead of a single feed-forward network (FFN), an MoE layer contains \(n\) separate FFNs (the ‘experts’) along with a router that decides which experts should process each token. Introducing these expert modules increases the model’s parameter count (and thus model capacity) without adding too much computational burden, since during inference only a subset of experts at each layer is used to process token embeddings. Although these additional FFNs are called ‘experts’ and are expected to learn different data distributions, in practice experts in pretrained MoEs do not necessarily show a clear routing pattern (see the routing analysis section in Mixtral of Experts).
In this post, I’ll propose a simple way to achieve routing compliance and speculate on how it can be used to encourage expert specialization via continued pretraining for downstream tasks.
Label-Supervised Routing
We will work with a pretrained dense model that is upcycled into an MoE. In sparse upcycling, the standard FFNs are replaced by expert FFNs, and in each layer the weights from the original FFN are copied into the experts. The routers are initialized randomly, and the resulting MoE is then finetuned further on the desired dataset.
The goal of expert specialization is to train the routers so that tokens from a particular ‘type’ of data are routed to a corresponding subset of experts. For example, suppose we care about three dataset types – math, code, and medical, and we have 6 experts per layer. In one possible design, we might want the first two experts to be active for math inputs, the next two for code, and the last two for medical inputs. During pretraining, if we have access to labeled data, we can deterministically ‘turn off’ the other experts and update only the domain-specific experts. During inference, however, we do not know the type of text being fed to the model, so this deterministic routing scheme is not directly applicable.
expert_map = {
"math": [1, 1, 0, 0, 0, 0],
"code": [0, 0, 1, 1, 0, 0],
"medical": [0, 0, 0, 0, 1, 1]
}
The idea behind Label-Supervised Routing is to train the routers on a labeled dataset in a supervised manner to circumvent the training-inference mismatch. If the model’s hidden dimension is \(d\) and there are \(n\) experts for each of the \(k\) domains, then the router is essentially a \(d \times nk\) matrix whose output, after applying \(\text{softmax}\), is a probability distribution over the \(nk\) experts. We then train it with a simple objective that increases the probability mass assigned to the experts designated for the token’s domain, effectively teaching the router a ‘domain-to-experts’ mapping. Since we expect to have enough data from each domain in the pretraining corpus, the router should be able to learn this behavior reliably. More concretely, for an \(L\)-layer network and \(T\) tokens, the expert routing loss is
\[\frac{1}{LT}\sum_{l=1}^{L}\sum_{t=1}^{T} -\log\!\left(\mathrm{softmax}\!\big(r_l(x_{l,t})\big)\cdot m\right),\]where \(r_l(\cdot)\) outputs router logits over \(E\) experts at layer \(l\), \(x_{l,t}\) is the token hidden state at layer \(l\), and \(m\in\{0,1\}^E\) is the expert-map for that domain, or in other words, it aims to maximize the router’s total probability mass on the domain’s allowed experts at every layer/token.
Experiments
While there is an abundance of open-weights, decoder-based Transformer models, upcycling dense models into MoE architectures comes with significant memory requirements. Adding only 4 experts per layer to a 1B model results in roughly 4B parameters. Given my hardware constraints, I experimented with the Llama 3.2 1B model. Upcycling it to use 6 experts per layer across 3 domains (with 2 active experts per domain) resulted in about 5.5B parameters in total. I chose math, code, and medical datasets, and randomly sampled 5,000 datapoints from each of zen-E/GSM8k-Aug-NL, PsiPi/CodeAlpaca_20k_NoBlanks, and qiaojin/PubMedQA on Hugging Face. I used a simple prompt template so I could construct a loss mask and train only on the response tokens given a question. Initially I tried training with cross-entropy plus the routing loss as an auxiliary term, but this hurt performance across domains. For this phase, I therefore froze all model parameters except the routers, which reduced the number of trainable parameters to roughly 200K. I trained for one epoch on 15,000 total datapoints using the AdamW optimizer with a batch size of 4, gradient accumulation steps of 8, and a fixed learning rate of \(5 \times 10^{-4}\).
Router Analysis
To check whether training the routers in this way induces routing compliance, I examined the router’s output probabilities for tokens from different domains. For a given domain with expert-map \(m\in\{0,1\}^E\) and router probabilities \(p_{l,t}\in\mathbb{R}^E\), I define per-token compliance as \(c_{l,t}= \sum_{e=1}^{E} m_e\, p_{l,t,e}\), i.e., the total probability mass the router assigns to the allowed experts. In the plots below, I show this compliance metric for a few randomly selected layers on one input from each domain’s test set. From the diagrams below, we can see that tokens are largely routed to their intended experts. The first few tokens are less strongly aligned with the expert map than the last few tokens, which makes sense: with limited context early in the sequence, the router has less information to infer the domain, but its confidence increases as it observes more tokens.
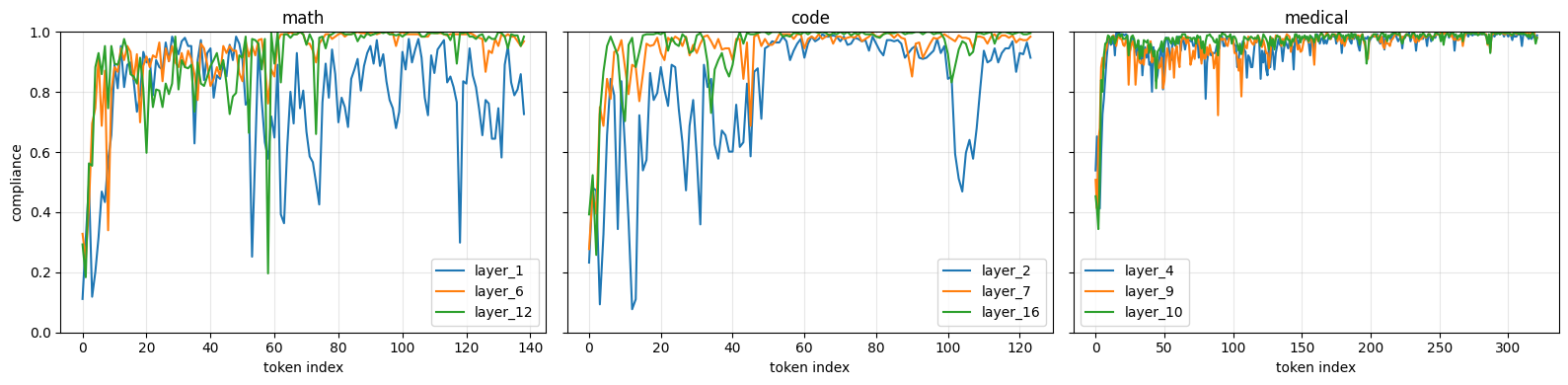
Router compliance in different layers for inputs from different domains
What’s Next?
While the proposed approach addresses routing compliance, it does not guarantee expert specialization. My initial experiments suggest that naively combining the next-token prediction loss with the expert routing loss does not interact well with the model parameters, which makes me think a two-stage approach is needed. In the first stage, we freeze all model parameters except the routers and train them using the expert routing loss. In the second stage, we freeze the routers and train the remaining parameters with a round of domain-specific SFT. The open question is whether this training recipe will eventually produce experts that are functionally specialized rather than just compliant with a routing policy.
The code for this work is available here.