translit-former: A Transformer That Speaks Bengali (Kinda)
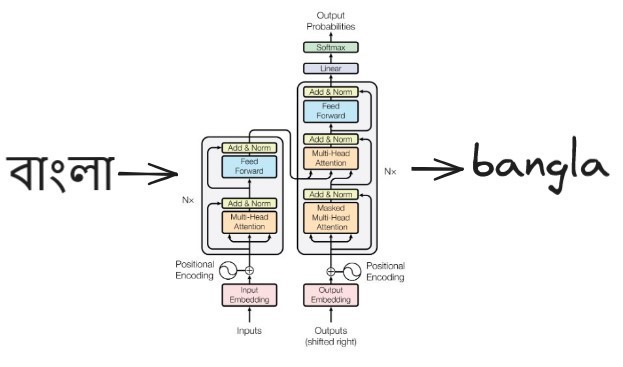
translit-former
For the last couple of days, I’ve literally put all my hobbies on hold and have been playing The Last of Us Part II. I finished it yesterday and still can’t get it out of my head. But before TLOU2 dropped on PC, I worked on a project which is what I want to talk about in this post.
I’ve been meaning to work on something that uses a transformer-based model. My goal was to basically write the model from scratch and then train it on a dataset to verify that it worked correctly. Initially, I planned to use a small text dataset to train a mini language model, nanoGPT-style. After searching for a while, I found a Kaggle dataset containing subtitles from all Marvel movies to date. But after working with it a bit, I felt the dataset just wasn’t large enough for a small language model to generate anything interesting.
The Dataset
I have the Google Indic Keyboard app installed in my phone for a while now and have always admired how accurate it is. You type something in English and it suggests a phonetically equivalent, coherent, and meaningful Bengali word. It saves a lot of time because you don’t have to turn on Bengali keyboard. I thought this could be a fun toy problem that probably wouldn’t require a huge dataset. I also figured finding the dataset wouldn’t be an issue as I could use ChatGPT or one of the existing phonetic parsers on GitHub to transliterate a Bengali text file.
Some of the phonetic parsers I came across (this and this) seemed promising at first but turned out to be not that great. So I kept looking for a clean and compact dataset, and eventually stumbled upon the bangla-corpus repo, which led me to the Dakshina dataset. Google released this dataset a few years ago, and it contains transliteration data for Bengali and a bunch of other Indian languages. It has around 40k Bengali-English transliterated pairs, which I split into train and test sets.
The Model
I started with a plain-vanilla GPT-style, decoder-only transformer. The vocabulary is simply the set of all unique characters in the dataset. For each Bengali-English word pair, I separate them with a </s> token; so at first we have the Bengali word and then the English word which ends with the </s> token before being padded with the same. So if the Bengali word is আমি and its English transliteration is ami, the input would be a list of token IDs corresponding to: ['আ', 'ম', 'ি', '</s>', 'a', 'm', 'i', '</s>', '</s>', ...'</s>']. I didn’t experiment much with different model dimensions or number of blocks, but you can find more details about the model architecture, batch size, etc., in the config file.
I made a couple of (mostly silly) bugs while coding up the model, which I’ll note down in this section. I had read the original Attention paper a while back and felt I understood it fairly well, thanks to the wonderfully written Annotated Transformer. But coding it up yourself is a whole different thing altogether.
-
Once I had the first draft of the model written, I tried training it on the training set and noticed that while the loss was definitely decreasing at first, it started to stagnate after a while (around 100 epochs or so). This turned out to be a silly mistake. I was using the exponential LR scheduler with the gamma parameter set to 0.9, which was basically making the learning rate too small after a few number of epochs, so the model stopped learning since the weights weren’t really getting updated anymore. I changed the parameter value from 0.9 to 0.99, and that fixed the issue (I could have started with a bit higher learning rate too, now that I think of it).
optimizer = optim.Adam(lm.parameters(), lr=0.005) scheduler = optim.lr_scheduler.ExponentialLR(optimizer, gamma=0.9) for _ in range(100): scheduler.step() print(scheduler.get_last_lr()) # [1.3280699443793783e-07], which is too small -
Once this was fixed, the training seemed to be going okay loss-wise. But when I enthusiastically fed a few Bengali words as input to the model, it spit out gibberish. But how come the training loss is so low then? While testing with new words, I was constructing the input like this:
<bengali word tokens></s></s> ... </s>, thinking that the</s>tokens wouldn’t really matter since I wouldn’t ‘attend to’ them anyway while transliterating. That’s true, but it turned out to be the opposite of what was happening during training.To understand this, we need to revisit the internals of each transformer block. Basically, what happens is that you have a numerical representation of each token in your input sequence as the entry point to each block. Within the block, you recalculate those representations by attending to other tokens (i.e., all the tokens that appear before a particular position, if you’re working with a GPT-like model). Each numerical representation goes through three transformations, resulting in three vectors for each token: the query, the key, and the value. Then, you perform a dot product between the query and the keys to obtain the ‘weights’, which are later used to calculate a weighted sum of the values to get the final representation. If you have multiple heads operating in parallel within each block, you calculate a weighted sum of the lower-dimensional values within each head, and then concatenate all the values from all the heads to get the new value with the original dimension.
So each of these query, key and value (\(Q, K \text{ and } V\)) when considering all the tokens in the context would be of dimension
batch_size, num_heads, context_length, d_head, so that within a head when you do \(\text{softmax}(QK^T / \sqrt{d_k})\), its shape becomesbatch_size, num_heads, context_length, context_lengthand then you multiply this with V, everything works out and you get back your original shapebatch_size, num_heads, context_length, d_head.To get Q, K, and V, you can simply do one matrix multiplication, but I was calculating them separately and reshaping them as shown below.
query = self.W_q(x).reshape(-1, config.num_heads, config.context_length, config.d_head) key = self.W_k(x).reshape(-1, config.num_heads, config.context_length, config.d_head) value = self.W_v(x).reshape(-1, config.num_heads, config.context_length, config.d_head)See what I was doing wrong? So,
xhas the shapebatch_size, context_length, d_model. Also,W_qis ad_model x d_modelmatrix. So when you doW_q(x), shape of the output becomesbatch_size, context_length, d_modeland then you are supposed to divide thed_model-dimensional vector intonum_headsnumber ofd_head-dimensional vectors. But because of the way I’m reshaping above, information from later tokens ended up leaking into the representation of the current token. So, the right order of reshaping should be:batch_size, context_length, d_model->batch_size, context_length, num_heads, d_head-> then transpose it to getbatch_size, num_heads, context_length, d_head. To fix this we can do the following instead:query = self.W_q(x).reshape( -1, config.context_length, config.num_heads, config.d_head ).transpose(1, 2) key = self.W_k(x).reshape( -1, config.context_length, config.num_heads, config.d_head ).transpose(1, 2) value = self.W_v(x).reshape( -1, config.context_length, config.num_heads, config.d_head ).transpose(1, 2)This was a very subtle bug and it took me a while to find it.
-
While reading the paper, I was not careful enough to notice that we have these projection layer that comes after the self-attention operation. This is different than the position-wise Feed Forward Nets that you apply outside of self-attention. My initial implementation was missing this.
-
I also realized that treating it like a language model with causal self-attention probably doesn’t make sense because, for the task of transliteration, you want to attend to the whole word provided. In other words, you want the representation of each token in the context word to attend to all the tokens in that word. So, I decided to use Prefix-LM masking, and I noticed that this definitely sped up the training process.
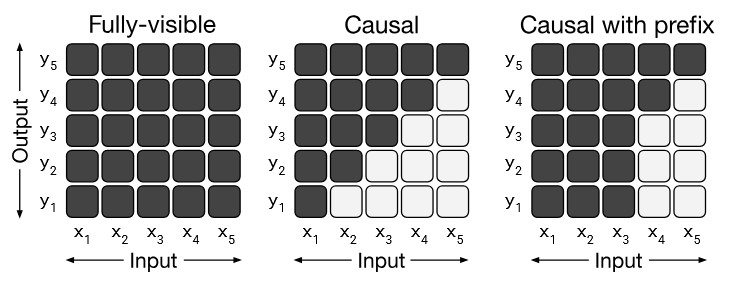
Different types of attention masking from the T5 paper
- The last change I made was after I realized that I was naively calculating the loss as the negative sum of log-probs for all the tokens. This meant that I was also counting the loss for predicting all the padded
</s>tokens at the end after the actual transliteration was completed, as well as the tokens in the Bengali word itself. I later fixed this by using only the log-probs of the tokens that actually matter (i.e., all the tokens between the first two instances of the</s>token), masking out the irrelevant ones.
Evaluation
After being trained for about 60 epochs, the model seemed to start overfitting the training set, but anything between epochs 35 and 50 worked similarly in my experiments. I used the nltk library to calculate character error rates (CER) for the words in the test set, and epoch 40 seemed to perform the best (with around ~0.16 CER). Here’s an example transliteration of a sentence I copied from Gora, and the model seemed to work pretty well, I’d say.
best_epoch = 40
checkpoint = torch.load(
f"checkpoints/epoch_{best_epoch}.pt",
weights_only=True,
map_location=device
)
lm.load_state_dict(checkpoint['lm_state_dict'])
lm.eval()
text = "এমন দিনে বিনা কাজের অবকাশে বিনয়ভূষণ তাহার বাসার দোতলার বারান্দায় একলা দাঁড়াইয়া রাস্তায় জনতার চলাচল দেখিতেছিল।"
for t in text.split(" "):
print(t, transliterate(t, lm, tokens))
এমন emon
দিনে dine
বিনা bina
কাজের kajer
অবকাশে abokashe
বিনয়ভূষণ binoybhushan
তাহার tahar
বাসার basar
দোতলার dotolar
বারান্দায় baranday
একলা ekla
দাঁড়াইয়া daraiya
রাস্তায় rastay
জনতার jontar
চলাচল cholachol
দেখিতেছিল। dekhitechilo
Conclusion
This was fun! The moral of the story: you need to be really careful with the dataset, internal tensor dimensions, how you calculate loss, and every tiny detail you can think of when training your transformer. Otherwise, it may work, but not in the way you intend. Alright, enough talking; now I’m going to dive back into the Lost Levels!
P.S. All the code and the evaluation notebook can be found here.